4.1 從大詞彙到大領域
1980年代時對大詞彙的定義是1000詞以上[45],例如李博士實驗用的語料庫共997詞。如今大詞彙系統的詞彙量都是上萬起跳,甚至可多達百萬詞。儘管如此,不同領域的詞彙是永遠也學不完。當Siri還沒被蘋果公司收購以前是以多個應用選項的App方式提供語音互動服務,也就是使用者透過點選某一個圖標來進行該應用領域的問答。等到2011年Siri正式成為iPhone 4S上的語音助理時,所有的應用領域全部被整合起來,從此Siri就以一個萬事通的姿態出現。其實,不限領域的口語辨識是不可能的 ,但是能夠處理很多領域的「大領域」口語辨識卻成了未來必然的挑戰。這當中也隱含了能夠識別瞭解領域語境並進而轉換或適應領域的可能性,甚至動態搜尋、或自動學習新領域的能力,也是未來非監督式機器學習的重要挑戰。
4.2 從非特定語者到非特定錄音
1980年代非特定語者辨識系統所使用的訓練語料,其語者數不到百位,如SPHINX系統的訓練語料含80名語者;但現今系統的訓練語料都是千人等級以上。其實語者並非唯一的語音訊號變異因素。語音訊號的來源,從錄音語者、錄音雜訊、到錄音通道,構成了三個主要的變異因素。
- 錄音語者:性別、年齡、口音、教育、職業等語者變異因素
- 錄音雜訊:錄音環境中除了錄音語者以外的其他聲音來源(包含其他語者、錄音設備),都構成了語音訊號以外的雜訊
- 錄音通道:所謂通道(channel),是指語音訊號從語者發出,經錄音設備轉換成數位音訊數據、並傳送給口語辨識系統為止,整個能量傳輸轉換的管道。進一步可細分為:
(1)聲能聲波傳輸(從語者到麥克風,含空間響應影響)、
(2)聲能電能轉換(即麥克風)、
(3)類比電訊傳輸(包括類比電路與儲存,如放大器、錄音帶等)、
(4)類比數位轉換(取樣率、位元數)、
(5)數位通訊傳輸(包含語音壓縮編解碼、封包延遲遺失等失真)。
顯然非特定語者只是挑戰之一,其他還有雜訊影響與通道效應對訊號造成的失真。其實,從上世紀80年代以來,許多的研發努力都是要克服這些變異因素對口語辨識造成的不利影響。其中主要分成語音特徵和語音模型兩種手段:也就是特徵計算或模型訓練,能夠盡量考慮不受語者、雜訊、以及通道變異的影響。例如各種特徵向量正規化與轉換演算法,或是上世代的標準聲學模型─GMM高斯混合模型等,都是成功的範例。但是自從2010年之後,以DNN作為聲學模型,更是成功的將特徵計算與模型訓練溶為一爐:深度神經網路的前幾層可產生強健的特徵向量;後幾層則代表高鑑別度的語音模型。而這正是這一波深度學習造成口語識別技術革命的秘訣所在。
2014年11月6日Amazon推出Echo以後,長距離(distant)或遠距(far-field)口語辨識已成為熱門應用需求。有別於傳統電話或近距離麥克風,這種應用情境更具有未來性。早在《2001太空漫遊》(2001: A Space Odyssey) 或《星艦迷航記》(Star Trek) 電影的場景中,人類跟電腦的對話都是透過無形的麥克風與喇叭。為了能夠遠距收音,就要採用高靈敏度與高動態範圍的麥克風[47],但這也意味環境雜訊的影響也更大。另外,不同房間產生不同的空間響應也使錄音通道效應的影響更劇烈。最後,在開放空間中,有許多人同時說話,要能從中辨識特定語者的語音指令(其他人說話的聲音成為干擾雜訊),將更是挑戰的問題。總之,雖然上世代非特定語者語音辨識的挑戰基本已經被克服,但未來隨著口語辨識應用的多元與擴大,以及人們對科技的期待提高,對於各種惡劣條件與高度變異下的錄音訊號來源,仍將持續挑戰新世代的研究者。
4.3 從連續口語到即興口語
1980年代時候的口語辨識系統大多是獨立詞(isolated word)辨識,也就是使用者一次只能說一個詞,而非一般說話這樣連著講整句話,後者就被稱為連續話語。其實正常口語本來就都連著講,因此連續口語(continuous speech)以一般用語而言是有點畫蛇添足,這完全是技術用語。在三十年前要能將連續話語辨識解碼出來的確是一項挑戰;但於2000年左右「加權有限狀態轉換器」WFST (Weighted Finite-State Transducer)技術被用來作為連續口語辨識解碼器之後[48][49][50],基本上連續口語辨識的挑戰也被解決了。 口語作為人機介面的特色之一就是可以免動手(hands-free)、改動口,以及免動眼(eyes-free)、改動耳,但是未來將更進一步希望能達到免動腦(mind-free)─意思是讓人跟機器交談可以避免心理負擔,不需要事先想好要說什麼,可以更輕鬆自在,就像跟人講話一樣。目前的系統能處理的語音輸入稱為讀稿口語(read speech),也就是語者必須先在心裡打好草稿─想好要說的話,然後才對機器講出來。但我們平常跟人講話不是這樣,而是邊想邊講、邊講邊想,想到哪講到哪,所以講的內容比較凌亂不全、甚至參雜錯誤與修正,但終歸會把自己的意思表達出來,這樣的風格稱為即興口語(spontaneous speech)。 其實只要沒有讀稿、背稿,平常說話都是即興語音,例如上課演講、開會討論、電話交談等等都是。目前已有的即興口語辨識應用就是客服電話錄音的自動文字轉寫(transcription),但以目前技術水準而言,大概字正確率在50%左右。即使經過對特定領域進行調適之後,大概也只能達到70%左右。這與讀稿口語辨識都可以達到90%的正確率而言,還有相當明顯的差距。表3 是一個即興口語辨識的實際測試實驗結果:包含五段客服電話錄音,以及三個商用辨識引擎。其中,即便是世界領先的Google雲端語音,平均辨識率還不到50%。J引擎是專門針對客服電話錄音轉寫應用的產品,平均剛過50%;T引擎則是針對讀稿口語的聽寫(dictation)應用產品,平均甚至不到20%。
表3 即興口語辨識測試例(字正確率):五段電話錄音、三個辨識引擎
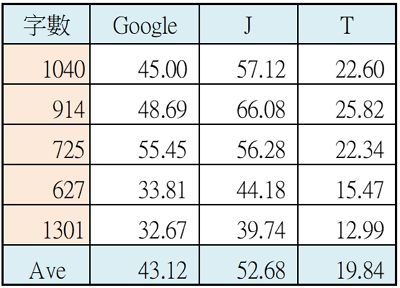
相對於讀稿語音,即興口語的辨識率會低很多,主要是因為其音韻變異性、語言非正規性、以及副語言(paralanguage or para-verbal)等,更多的態樣變化與非標準語言現象,這使得依據讀稿口語跟標準語言所訓練的聲學模型跟語言模型,都難以跟即興口語進行匹配。即興口語的各種現象非常繁雜,本文以中研院針對現代漢語口語對話語料庫所定義的標記分類[51]為基礎,再參考多份文獻[52][53][10]重新歸納整理如下,共三大部分的即興口語現象,並以現代漢語為例:
1 一般口語語音(ordinary speech sounds):具有語意或語法功能的口語部分
1.1 自然音韻變化(natural phonological variation):因前後音緊接的自然音韻規律變化
1.1.1 音的同化(assimilation):e.g.川普/tʰʂan pʰu/→[tʰʂam pʰu]
1.1.2 音節合併(syllable contraction):e.g.我們→[om]、這樣→醬[tɕiaŋ]、就是→[tɕioʅ]
1.2 不當音韻偏差(inappropriate phonological variation):因個人發音問題的音韻偏差
1.2.1 拖長音(lengthening):e.g.我目前是從事~~外貿(『事』拖長)
1.2.2 鼻化音(nasalized):e.g. 大家/tɕia/→[tɕiã](『家』的母音唸成鼻化母音)
1.2.3 發音偏差(inappropriate pronunciation):e.g.我比較喜歡(『比』發成[pu2])
1.3 難以辨識的語音(unintelligible speech sound)
1.3.1 喃喃自語(mumble):說話者無意讓對方聽見而小聲的喃喃自語,但可辨識音意字。e.g.都在賺錢喔賺錢(最後「賺錢」為說話者小聲的喃喃自語)
1.3.2 不確定字音(uncertain):只能辨識音,也可猜測部分字、與大致語意。
1.3.3 無法辨識的語音(unrecognizable speech sound):無法辨識任何音意字之語音。
1.4 不流暢的語流(disfluency)
1.4.1 語流中斷音韻不順(prosodic disfluency)
1.4.1.1 沉默(silence):對話者因話題銜接不上,產生雙方語流間之中斷沈默。
1.4.1.2 停頓(pause) :語者自身語流之中斷暫停,中斷明顯、致韻律不流暢。
1.4.1.3 字詞殘破(word fragment):語詞有減。e.g.是進口[k]嗯出口(口[ko3]只唸一半)
1.4.1.4 口吃(stutter):語詞有增、重複、遲滯。e.g.外國→[u5] wai4 guo2。
1.4.2 語句中斷語法不當(lexico-syntactic disfluency)
1.4.2.1 句子未完被打斷(interrupted):語法未完整前即因對方打斷而被迫中斷句子。
1.4.2.2 句子未完而中斷(abridged):語法未完整前即中斷句子,並且重新開始新句。
1.4.2.3 句法不當(inappropriate usage):語意大致完整,但語句不合句法。
1.4.2.4 語詞有誤(error):詞彙、成語、諺語的錯誤使用。e.g.一張汽車。
1.4.3 重複或修正(repetition or repair):重複/錯誤詞語[修正插語]正確詞語
1.4.3.1 詞語完整重覆(repetition):e.g.可是又有又有這個情理法
1.4.3.2 詞語部分重覆(restart):e.g.覺得很很不很不夠用這樣
1.4.3.3 詞語錯誤修正(repair):e.g.你您的住處、當時我才反應到我才意識到說修正可包含:語意、語詞、語音
1.4.3.4 重複或修正插語(editing term):e.g. 我是直嗯直升機飛行員、是進口嗯出口嗎
1.5 受外語、方言、等社會面影響(socio-linguistic phenomena)
1.5.1 語言轉換(code switching):e.g.很大的看板[k'aN2] [paN4]、有Hangten和Giordano的衣服
1.5.2 受閩南語影響之發音:e.g. 真的很熱[lə4]、飛機[huei]
1.5.3 約定俗成讀音:與字典標準不同。e.g. 符[fu3]合、嗎[ma1]、關係[ɕi1]、正妹[mei1]
2 語用口語語音(pragmatic speech sounds):以語用功能為主的口語部分
語用功能為主之「語氣助詞」或「插說歎詞」。在實際口說時會因情感與情境因素而有強烈音韻變化,因此雖然有些有對應文字,但該文字之標準音韻與實際發音會有落差(如『嗯』);甚至有部分語聲難以找到相應語意或發音的文字,只能以擬聲詞(如『呃』)或聲音標記(如『UM』)代表。另有些字詞雖原具有明確音意,但當以語用功能為主時,去除之後對語意幾無影響,例如:「那個」、「然後」、「對」等詞語,常常在口語中被作為停頓猶豫功能的插說語,去除後對語句的語意跟語法都沒有影響。
2.1語氣助詞(modal particle):語法上附著於句末,用以表示說話時的語氣(mood or mode)。這類語氣詞的用字聲調通常是輕聲、發音輕而短,故前後音連讀容易發生協同發音(coarticulation)音變效應。
2.1.1 基本語氣詞:的、了、麼、呢、吧、啊。按語氣類型(modality)分類如下
2.1.1.1 肯定語氣:的、了
2.1.1.2 疑問語氣:麼、呢
2.1.1.3 強烈肯定:呢
2.1.1.4 半信半疑:吧
2.1.1.5 感嘆語氣:啊
2.1.2 疊用語氣詞:連用兩個基本語氣詞,常會產生音節合併、甚至形成新字
2.1.2.1 {的、了}+{麼、呢、吧、啊}:e.g.了+啊=啦
2.1.2.2 {麼、呢}+啊:麼+啊=嘛(肯定)/嗎(疑問)、呢+啊=哪
2.1.3 『啊』/a/受前一字發音影響而產生音變,甚至形成新字
2.1.3.1 前音為ㄧ或ㄩ:/a/ → [ya](啊→呀)e.g.是你啊→是你呀、老許啊→老許呀
2.1.3.2 前音為ㄨ或ㄠ:/a/ → [wa](啊→哇)e.g.苦啊→苦哇、好啊→好哇
2.1.3.3 前音為[n]:/a/ → [na](啊→哪)e.g. 做人啊→做人哪、好好幹啊→好好幹哪
2.1.3.4 有音變、但無對應字:e.g. 唱啊/a/ → [nga]、什麼事啊/a/ → [ra]
2.2 插說歎詞(interjection):語法上單獨成句、隨處可插。按照語用功能分類如下
2.2.1 驚嘆(exclamations):表達瞬間情感。e.g. 啊、呀、哎呀、哎喲、天呀、唉、嗄(ㄚˊ)。
2.2.2 咒罵(curses or profanities):對人或自己表達情緒。e.g. 哼、啐、呸、誒(ㄝˋ)。
2.2.3 招呼(greetings):招呼對方、開啟交談。e.g.喂、嗨、哈囉(Hello)、欸(ㄟˋ)。
2.2.4 回應(response):交談中回應對方以保持交談、或反應聽者態度。
2.2.4.1 交談篇章標記(discourse markers):語聲(e.g. MH、HON、HEN)或語詞(e.g.喔、嗯、是),用來回應確認對方的發言,使對方保持發言權。
2.2.4.2 反應聽者態度:肯定(如UH、對)、否定(噯/ㄞˇ/、不)、疑惑(咦、哦)
2.2.5 猶豫(hesitation):發言中補白(fillers)─語聲(如UH、UM)或語詞(如「那個」、「然後」、「對」),用來停頓思考,且不希望聽者以為已經講完,使自己保持發言權。
3 非口語之人聲(non-speech human sounds):非口語的人聲部分
舉凡非語音但由人所發出的聲音,例如心理因素(笑聲、哭聲、嘆氣聲、嘖舌聲、咂嘴聲)、生理因素(呼吸聲、吞口水聲、清喉嚨聲、咳嗽聲、噴嚏聲、打嗝聲、哈欠聲)、或其他因素由口腔發出無法辯識的聲音等。根據和語言內容的關係,或副語言功能分析,可有如下不同的分類方法:
3.1 有無伴隨語言內容:該人聲是否跟語言內容重疊?e.g.笑著說話vs.獨立笑聲
3.2 有無副語言功能:純粹生理偶發因素的人聲,還是具有副語言功能?e.g.「咳嗽聲」可能是純粹偶發的生裡現象;但也可用來表達招呼警告的語用功能。「嘖舌聲」可能是說話中發聲器官偶然產生的聲音;但也可用來表達驚奇或諷刺的態度。
從以上歸納的即興口語現象,就可看出其複雜度。也可以知道機器要辨識理解人類生活中的即興口語還有相當的距離,更不用說到高層次的思維理解:如科學的推理、文學的賞析、甚至哲學的思辯等。但正如在第2章所提到的,未來的方向是口語理解,因此不但要辨識語音,還要處理構詞、分析語法,解讀語意,甚至處理篇章語用問題。上述即興口語現象,就是包含了從語音、語詞、語法、語意、直到語用的各個層面,因此很顯然未來的挑戰,自然是從「語音辨識」往「口語理解」不斷深化的演進方向。
總結本文,深度神經網路的模型訓練技術以及架構規劃在近八年來日趨成熟,口語辨識也因此吹起一陣深度學習風潮,帶來的是比以往更有感的辨識率提升。工業技術研究院的自然口語技術團隊深耕深度學習四年有餘,早已將FNN和LSTM引入自主開發的口語辨識引擎,並搭配運算加速技術,無論在雲端還是設備端皆能提供更準確的口語辨識,提高人機互動的親和力。本文趁此風潮方興未艾之際,除了回顧深度學習快速崛起與口語辨識技術密切關係的歷史外,也重新釐清界定口語辨識技術的正確用語和真實內涵,並且說明DNN在口語辨識技術的現況與展望,最後更提出了新世代的口語辨識技術三大挑戰做為未來進一步研發的參考方向。
1國際音標IPA (International Phonetic Alphabet) 規定以/ /符號表示音位,以[ ]符號表示語音,本文中均遵循此一規範。
2李開復去年演講人工智慧趨勢時,在簡報中有一頁提到:「跨領域NLU根本不存在!」;並以詼諧但強烈的口吻在下面註解:「不!要!問!我!為!什!麼!」[44],充分表達出對一般人誤解的無奈。
參考文獻
[1] Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural networks, 61, 85-117.
[2] Chris Manning, Lecture 1 | Natural Language Processing with Deep Learning, (CS224n/Ling284), Stanford University, 30:12 / 1:11:40, YouTube. April 2017.
[3] Chris Manning and Richard Socher, Natural Language Processing with Deep Learning (CS224n/Ling284), Stanford University, Lecture 1: Introduction, p.16, Jan. 2018.
[4] Dahl, G., Yu, D., Deng, L., and Acero, A. (2012). Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. Audio, Speech, and Language Processing, IEEE Transactions on, 20(1):30–42.
[5] G. Hinton et al., "Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups," in IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82-97, Nov. 2012. doi: 10.1109/MSP.2012.2205597
[6] Li Deng, Keynote speech, NCMMSC 2011 - National Conference on Man-Machine Speech Communication, NCMMSC2011, Xi'an China, Oct. 17, 2011.
[7] Li Deng, A Tutorial on Deep Learning for Signal and Information Processing, Asia-Pacific Signal and Information Processing Association, Annual Summit and Conference, APSIPA ASC 2011, Xi'an China, Oct. 18, 2011.
[8] Longman Dictionary of Contemporary English 5th Edition, Pearson Longman; 5th edition (January 21, 2009).
[9] V. Fromkin, R. Rodman, and N. Hyams, An Introduction to Language (7th Edition), Thomson Heinle, (2003).
[10] 謝國平:語言學槪論,臺北,三民書局 (1985)
[11] Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., & Lang, K. J. (1990). Phoneme recognition using time-delay neural networks. In Readings in speech recognition (pp. 393-404).
[12] Denham, Kristin; Lobeck, Anne (2009), Linguistics for Everyone: An Introduction, Cengage Learning, p. 89.
[13] Chris Manning and Richard Socher, Natural Language Processing with Deep Learning (CS224n/Ling284), Stanford University, Lecture 1: Introduction, p.4, Jan. 2018.
[14] J. Clark and C. Yallop, An Introduction to Phonetics & Phonology, Basil Blackwell, (1990).
[15] Shapiro, Stuart C. (1992). Artificial Intelligence In Stuart C. Shapiro (Ed.), Encyclopedia of Artificial Intelligence (Second Edition, pp. 54–57). New York: John Wiley. (Section 4 is on "AI-Complete Tasks".)
[16] G.E. Hinton and R.R. Salakhutdinov, “Reducing the Dimensionality of Data with Neural Networks,” in Science 28, Jul. 2006.
[17] Geoffrey Hinton (2010). A Practical Guide to Training Restricted Boltzmann Machines. UTML TR 2010–003, University of Toronto
[18] D. Yu and L. Deng, “Automatic Speech Recognition: A Deep Learning Approach, “ in Signal and Communication Technology series, Springer-Verlag London, 2015.
[19] D. Povey et al., “The Kaldi Speech Recognition Toolkit, “ in ASRU 2011.
[20] X. Huang, A. Acero, and H.-W. Hon, “Spoken Language Processing, “ Pearson Education Taiwan Ltd., 2005.
[21] T.F. Quatieri, “Discrete-time Speech Signal Processing, “ Pearson Education Taiwan Ltd., 2005.
[22] X. Zhang, J. Trmal, D. Povey, and S. Khudanpur, “Improving Deep Neural Network Acoustic Models Using Generalized Maxout Networks, “ in IEEE ICASSP 2014.
[23] R Hahnloser, R. Sarpeshkar, M A Mahowald, R. J. Douglas, H.S. Seung, “Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit, ” in Nature. 405. pp. 947–951.
[24] X. Glorot, A. Bordes, and Y. Bengio, " Deep Sparse Rectifier Neural Networks, " in PMLR 15, pp. 315-323, 2011.
[25] S. Hochreiter and J. Schmidhuber, “Long short-term memory, “ in Neural Computation, 9(8):1735–1780, 1997.
[26] A. Graves, A. Mohamed, and G. Hinton, “Speech Recognition With Deep Recurrent Neural Networks, “ in IEEE ICASSP 2013.
[27] A. Hannun, A. Mass, D. Jurafsky, and A. Ng, “First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs, “ in arXiv:1408.2873, 2014.
[28] T.N. Sainath, B. Kingsbury, G. Saon, H. Soltau, A. Mohamed, G. Dahl, and B. Ramabhadran, “Deep Convolutional Neural Networks for Large-scale Speech Tasks, “ in Neural Networks, 64 (2014), pp. 39-48.
[29] A. Krizhevsky, I. Sutskever, and G. Hinton, “ImageNet classification with deep convolutional neural networks, “ in NIPS 2012.
[30] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition, “ in Proc. IEEE, 86 (11) (1998), pp. 2278-2324.
[31] A. Waibel, T. Hanazawa, G. Hinton, K. Shikano, and K.J. Lang, “Phoneme Recognition Using Time-Delay Neural Networks, “ in IEEE Trans. On Acoustics, Speech and Signal Processing, Volume 37, No. 3, pp. 328. - 339 March 1989.
[32] V. Peddinti, D. Povey, and S. Khudanpur, “A time delay neural network architecture for efficient modeling of long temporal contexts, “ in Interspeech 2015.
[33] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks, “ in Proceedings of the International Conference on Machine Learning, ICML 2006: 369–376.
[34] H. Sak, A. Senior, K. Rao, F. Beaufays, and J. Schalkwyk, “ Google voice search: faster and more accurate, “ in Google AI Blog, Sep. 2015.
[35] Y. Maio, G. Gowayyed, and F. Metze, “Eesen: End-To-End Speech Recognition Using Deep RNN Models And Wfst-Based Decoding,” in IEEE ASRU 2015.
[36] Y. Maio, G. Gowayyed, X. Na, T. Ko, F. Metze, and A. Waibel, “An Empirical Exploration Of CTC Acoustic Models, “ in IEEE ICASSP 2016.
[37] A. Graves, “Sequence Transduction with Recurrent Neural Networks,” in ICML Representation Learning Workshop, 2012.
[38] E. Battenberg, J. Chen, R. Child, A. Coates, Y. Gaur, Yi Li, H. Liu, S. Satheesh, D. Seetapun, A. Sriram, and Z. Zhu, “Exploring Neural Transducers For End-To-End Speech Recognition, “ in ASRU 2017.
[39] K. Rao, H. Sak, and R. Prabhavalkar, “Exploring Architectures, Data And Units For Streaming End-To-End Speech Recognition With RNN-Transducer, “ in ASRU 2017.
[40] D. Bahdanau, J. Chorowski, D. Serdyuk, P. Brakel, and Y. Bengio, “End-To-End Attention-Based Large Vocabulary Speech Recognition, “ in IEEE ICASSP 2016.
[41] W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, Attend And Spell: A Neural Network For Large Vocabulary Conversational Speech Recognition, “ in IEEE ICASSP 2016.
[42] Kai-Fu Lee , Raj Reddy, Large-vocabulary speaker-independent continuous speech recognition: the sphinx system, Carnegie Mellon University, Pittsburgh, PA, 1988.
[43] J. K. Baker, “The DRAGON system-An overview,” IEEE Trans. Acoust., Speech, Signal Processing. vol. ASSP-23, pp. 24-29, Feb. 1975.
[44] Jelinek, F.; Bahl, L.; Mercer, R. (1975). "Design of a linguistic statistical decoder for the recognition of continuous speech". IEEE Transactions on Information Theory. 21 (3): 250.
[45] Lee, K. F., Hon, H. W., & Reddy, R. (1990). An overview of the SPHINX speech recognition system. IEEE Transactions on Acoustics Speech and Signal Processing, 38, 35-45.
[46] 李開復:「我不是李開復,我是人工智能」。百人論壇,海南三亞萬豪酒店,2017-03-03。
[47] Hsien-Cheng Liao, Chih-Chung Kuo, and Cheng-Hsien Lin, “Challenges and Preliminary Study on Indoor Distant Speech Recognition”. ICL Journal 164. Dec. 25, 2015(廖憲正、郭志忠、林政賢:室內長距離語音辨識技術挑戰與初探。電腦與通訊 164期)
[48] M. Mohri, F. Pereira, and M. Riley, “Weighted finite-state transducers in speech recognition,” Comput. Speech Lang., vol. 16, pp. 69–88, 2002.
[49] M. Riley, F. Pereira, and M. Mohri, “Transducer composition for context dependent network expansion,” in Proc. Eurospeech, 1997, vol. 3, pp. 1427–1430.
[50] M. Mohri and M. Riley, “Weighted determinization and minimization for large vocabulary speech recognition,” in Proc. Eurospeech, 1997, vol. 1, pp. 131–134.
[51] 曾淑娟、劉怡芬:《現代漢語口語對話語料庫標註系統說明》,(2002),中研院
[52] 《語法初階》上海師範大學中文系 漢語教研室 (1997),書林
[53] 《中文詞類分析(三版)》詞庫小組技術報告93-05 (1993),中研院