工研院資通所 張傑智
語音是人類最基礎、方便的自然溝通表達方式,除了語言訊息的傳遞之外,也包含了聲音情緒等訊息。隨著全球智慧裝置以爆炸性的數量成長,語音已成為與智慧終端互動不可或缺的方式,因此若能瞭解使用者與智慧終端透過語音時進行互動的情緒,智慧終端將可根據使用者的情緒狀態進行適當的回應。而近年以人工智慧進行情緒辨識技術備受關注,國際研究機構(Gartner)指出,情感AI領域具產值估計高達200億美元,並有良好的發展潛力[1]。而本篇希望透過簡單的說明,讓一般讀者能瞭解語音情緒辨識的基本架構與做法,以及發展該系統要注意的事項。
精彩內容
1. 瞭解語音情緒辨識的基本概念
2. 語音情緒辨識系統架構與流程說明
3. 訓練語音情緒辨識器的5個步驟
|
語音情緒辨識系統概述
什麼是情緒辨識
所謂情緒辨識是透過感測裝置收集的訊號進行分析與處理,得出對方正處於的情感狀態,如圖1所示。
 圖1 透過智慧終端可分析音訊的情緒狀態
圖1 透過智慧終端可分析音訊的情緒狀態訊號來源主要可分為兩類,一是檢測生理訊號為主,例如心律、體溫等;二是偵測影像臉部表情、語音訊號等。而標記方式主要可分為兩類,一是以離散的語言標籤,例如以高興(hap)、中性(neu)、驚訝(sur)、興奮(exc)等作為情緒類別的語言標籤(圖2左下),在標記時會請標記人員先聽一個音檔的語音,再請標記人員針對這一段語音決定它的情緒類別;二是連續性的狀態標記,用PAD情緒狀態模型來衡量心理的情緒狀態,共有3個項目,分別為:愉悅度(PLEASURE/VALENCE)、激 活度(AROUSAL)、支配度(DOMINANCE),愉悅度代表情緒的正面與負面程度、激活度代表情緒的激動與緩和程度、支配度代表情緒的主導與順從程度,如圖2所示[2],在標記時會請標記人員聽一個音檔的語音,在聽語音的同時一邊操作PAD記錄軟體(圖2右下),標記人員會依語音連續播放時的愉悅度、激活度、支配度將滑鼠移動至足以代表當時正/負方向、程度大小的位置,後續可直接使用該次記錄下的連續數值或是計算求取平均值(圖2中下);因此在建構情緒辨識系統前,需要先瞭解手上有哪些情緒訊號的資料,以及標記狀況為何。
![圖2 PAD情緒狀態模型與情緒標記範例(資料來源:[2])](https://jictcms.itri.org.tw/files/file_pool/1/0M256566959433338567/Thumbnail%20%2844%29.png) 圖2 PAD情緒狀態模型與情緒標記範例(資料來源:[2])
圖2 PAD情緒狀態模型與情緒標記範例(資料來源:[2])語音情緒辨識系統架構
語音情緒辨識系統可區分為訓練階段和辨識階段兩個部分,如圖3所示:
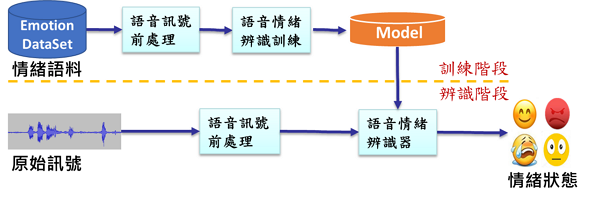 圖3 語音情緒辨識系統架構示意圖
圖3 語音情緒辨識系統架構示意圖在訓練階段首要的任務是訓練出一個好的模型供辨識器使用,而辨識階段則需要設計出一個好的辨識器架構、演算法與類神經網路,以便能獲得較佳的辨識結果,然而,在設計辨識器時往往又需要考量實際使用環境,是否有即時辨識的需求(架構複雜度),並需回頭看看手上有哪些可用的語料、數量為何、標記狀況為何等等,因此需針對實際的使用情境,審視手上可運用的資料,來決定出合適的架構,而且往往第一個版本應用到實際場域的效能常會不符合預期,因此需要不斷的收集實際語料進行標記,與調適訓練來進行系統的優化。
情緒語料
目前現今流行的基本感情項目為Ekman於1972年提出的憤怒(anger)、厭惡(disgust)、恐懼(fear)、快樂(happiness)、悲傷(sadness)、驚訝(surprise),在進行語料收集時一般會再加入中性(neutral)的情緒,而語音情緒的表現會因地域、語種、年齡的不同而有所差異,因此需審慎評估使用該資料庫的合適性,下面將介紹幾個常用的情感資料庫供參考[4]。 .Belfast英語情感資料庫:40位錄音者用5種情感傾向進行演講。 .柏林Emo-DB情感資料庫:10位演員7種情感,文本選取中性,要求演員表演前透過回憶自身真實經歷或體驗進行情緒的醞釀。 .FAU AIBO兒童德語情感資料庫:51名兒童10~13歲,透過與索尼公司的AIBO機器狗進行自然互動,從而進行情感資料的收集。 .CASIA漢語情感資料庫:兩男兩女透過演講得到的6種情感。 .ACCorpus系列漢語情感資料庫:50位錄音者對5種情感各自表演。 .IEMOCAP:10個演員,1男1女演繹1個session,共5個session。 ■錄製了將近12小時的資料,有視頻、語音、人臉的變動捕捉和文本。 ■包括即興自發和念稿表演,每個語句至少有3個人進行標記。 ■9種情感:憤怒、快樂、興奮(excitement)、悲傷,沮喪(frustration)、恐懼、驚訝、其它和中性)的離散標以及3個維度的維度標 籤(valence, activation and dominance)。 .NNIME中文情緒互動多模態語料庫:44位演員透過戲劇表演呈現情緒,錄製了將近11小時的聲音、影像與心電圖資料,共49個標記人員進行6 類情緒與PAD標記[13]。
語音訊號前處理
語音訊號前處理最主要可以分為特徵擷取(Feature Extraction)與資料標準化(Feature Scaling)兩個部分,降維處理(Dimensionality Reduction)可依情緒辨識器架構視情況是否進行,流程如圖4所示。
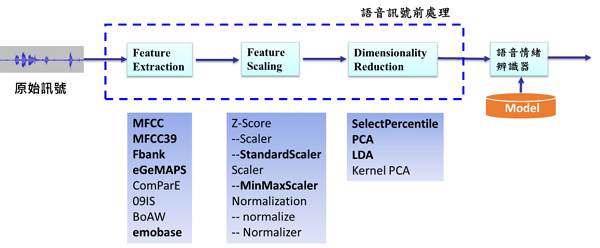 圖4 語音訊號前處理流程
圖4 語音訊號前處理流程特徵擷取前需要瞭解自已想要取得怎麼樣的語音特徵,是要針對該語句取得一組特徵,還是針對該語句的每個訊框(frame)取特徵;以及是要取得低階語音特徵(low level descriptors, LLDs)還是高階語音特徵(high level statistics functions, HSFs),確認所需要的特徵後,便可透過特徵擷取工具(例如:openSMILE、librosa、PRAAT)取得訓練程式所需要的語音特徵。 低階語音特徵主要分類如下: .語韻(prosodic):6個頻率相關特徵,包含Pitch(log F0,在半音訊率尺度上計算,從27.5Hz開始)、Jitter(單個連續基音週期內的偏 差)、前3個共振峰的中心頻率、與第一個共振峰的頻寬。 .頻譜(spectrum):9個譜特徵,包含Alpha Ratio(50~1,000Hz的能量和除以1~5kHz的能量和)、Hammarberg Index(0~2kHz的最強 能量峰除以2~5kHz的最強能量峰)、Spectral Slope 0~500 Hz and 500-1500 Hz、Formant 1, 2, and 3 relative energy (前3個共振峰的 中心頻率除以基音的譜峰能量)、Harmonic difference H1~H2 (第一個基音諧波H1的能量除以第二個基音諧波的能量)、Harmonic difference H1~A3。 .音質(voice quality):3個能量/振幅相關特徵,包含Shimmer(相鄰基音週期間振幅峰值之差)、Loudness(從頻譜中得到的聲音強度的 估計)、HNR(Harmonics-to-noise)信噪比。 高階語音特徵主要在LLDs的基礎上做一些統計而得到的特徵,例如:均值、最大值等等;或對運算8個函式,20百分位、50百分位、80百分位、20到80百分位之間的range,上升/下降語音訊號的斜率均值和標準差。 在這裡將介紹幾個大家常用的語音特徵: .MFCC:一般大家對於取得語音特徵,最直接想到的就是MFCC的特徵,而MFCC的流程如圖5所示,主要為取1個對數能量和12個倒頻譜參數, 而Fbank只少做MFCC的Inverse DFT步驟,而MFCC39則是對MFCC取delta和delta-delta。
![圖5 MFCC流程圖(資料來源:[7])](https://jictcms.itri.org.tw/files/file_pool/1/0M256568233791409584/Thumbnail%20%2847%29.png) 圖5 MFCC流程圖(資料來源:[7])
圖5 MFCC流程圖(資料來源:[7]).eGeMAPS:eGeMAPS是GeMAPS(The Geneva Minimalistic Acoustic Parameter Set)的擴充套件,在18個LLDs的基礎上加了一些特徵 [6],包括5個頻譜特徵:MFCC1-4和Spectral flux(兩個相鄰訊框的頻譜差異)和2個頻率相關特徵:第二共振峰和第三共振峰的頻寬;並對這 擴充套件的7個LLDs做算術平均和coefficient of variation(計算標準差然後用算術平均規範化)可以得到14個統計特徵。對於共振峰頻寬只在 voiced region做,對於5個頻譜特徵在voiced region和unvoiced region一起做;並在unvoiced region計算spectral flux的算術平均,然後只 在voiced region計算5個頻譜特徵的算術平均和coefficient of variation,得到11個統計特徵;並多加一個equivalent sound level,共得到14 +11+1=26個擴充套件特徵,加上原GeMAPS的62個特徵,得到88個特徵,這88個特徵就是eGeMAPS的特徵集。 .IS09:2009年InterSpeech上Emotion Challenge提到的特徵[6],總共有384個特徵,計算16個LLD,過零率,能量平方根,F0,HNR, MFCC1-12,然後計算這16個LLD的一階差分,可以得到32個LLD,對這32個LLD應用12個統計函式,最後得到32x12 = 384個特徵。 特徵選擇的好壞往往會影響到辨識結果,由於語音在情緒的表現和語韻有關,因此與語韻相關的特徵更能分辨出不同的情緒種類。 而資料標準化主要有3種手段Z-Score、Scaler、Normalization,除了要決定將所求取的特徵透過哪一種手段外,另外要注意的是該標準化的範圍是要針對每一句特徵、一個使用者的所有語句特徵、還是所有使用者的語句特徵來進行。 最後降維處理則需視所挑選的特徵與運行的情緒辨識器來決定是否進行。
語音情緖辨識器
語音情緒辨識器的設計將會直接影響到辨識的效果,一般在少量資料,且經過人工精心設計整理的資料特徵,可以使用傳統機器學習分類器來進行設計,若擁有大量資料的情況下,往往會使用類神經網路辨識器來進行設計,雖然現今類神經網路辨識器的效果往往會優於傳統機器學習分類器,但當透過類神經網路辨識效果不佳時,仍可回頭思考傳統機器學習分類器的可能性。 而訓練語音情緒辨識器主要的5個步驟如下: 1.選擇特徵(例如:eGeMAPS),並收集訓練資料(training set)、評估資料(validation set)、與測試資料(testing set)。 2.選擇效能指標(performance metric),需要先決定所處理標的是標籤型式的分類問題,還是連續數值的回歸問題。 .甲、分類指標:混淆矩陣(Confusion matrix)、ROC曲線(Receiver operating characteristic curve)、AUC(Area Under Curve)。 .乙、回歸指標:平均均方誤差(Mean Squared Error, MSE)、平均絕對誤差(Mean Absolute Error, MAE)、平均均方對數誤差(Mean Squared Logarithmic Error, MSLE)。 3.選擇分類器和最佳演算法 .傳統機器學習分類器的設計可選擇像是Logistic Regression、SVM、KNN、Decision Tree、GMM、HMM等方法,如圖6所示,透過統計模 型的方式來進行計算與分類。
![圖6 SVM與HMM示意圖(資料來源:[8][9])](https://jictcms.itri.org.tw/files/file_pool/1/0M256568814235388511/Thumbnail%20%2848%29.png) 圖6 SVM與HMM示意圖(資料來源:[8][9])
圖6 SVM與HMM示意圖(資料來源:[8][9]) .類神經網路辨識器的設計,由於語音是連續的訊號,而且訊號是有序且相關的,因此最直覺是使用循環神經網絡(RNN)來進行設計,而常見 的循環神經網絡有單/雙向的RNN(Recurrent Neural Network)、GRU(Gate Recurrent Unit)、LSTM(Long short-term memory), LSTM運作流程如圖7所示;而其它的衍生架構如卷積循環神經網絡(Convolutional Recurrent Neural Network, CRNN)、注意力機制 (Attention Mechanism)、端到端(End-to-End)[11]等在此不一一介紹。
![圖7 LSTM流程圖(資料來源:[10])](https://jictcms.itri.org.tw/files/file_pool/1/0M256569357861732565/Thumbnail%20%2849%29.png) 圖7 LSTM流程圖(資料來源:[10])
圖7 LSTM流程圖(資料來源:[10])而語音可使用的特徵除了基本聲學特徵(Basic Acoustic Features),亦可搭配使用頻譜圖(spectrogram),架構如圖8所示;或透過語音辨識(Speech Recognition)取得情緒示意詞等文字進行語音與文字之情感計算。
![圖8 搭配使用頻譜圖、CNN、LSTM、Attention架構示意圖(資料來源: [12])](https://jictcms.itri.org.tw/files/file_pool/1/0M256569417405701583/Thumbnail%20%2850%29.png) 圖8 搭配使用頻譜圖、CNN、LSTM、Attention架構示意圖(資料來源: [12])
圖8 搭配使用頻譜圖、CNN、LSTM、Attention架構示意圖(資料來源: [12])4.評估模型效能,透過評估/測試資料以上述第二點所選擇的效能指標,可以觀察到目前的模型效能表現為何。
在機器學習或深度學習領域,評估是一項必要的工作,而要評估一個模型的效能,往往需要透過一些指標來判斷,以分類問題常用的混淆矩陣為例,可觀察的指標有準確率(Accuracy)——預測正確的數量占總數量的比例、精確率(Precision)——該類別(Class)預測正確的數量占所有預測為該類別的比例、召回率(Recall)——該類別預測正確的數量占所有該類別數量的比例、F1:在每個混淆矩陣上計算精確率和召回率,最後計算平均值、UA(unweighted accuracy):分別計算每一個類別的準確率,然後求平均值、UAR(Unweighted Average Recall):分別計算每一個類別的召回率,然後求平均值,詳細計算方法可參考圖9所示。
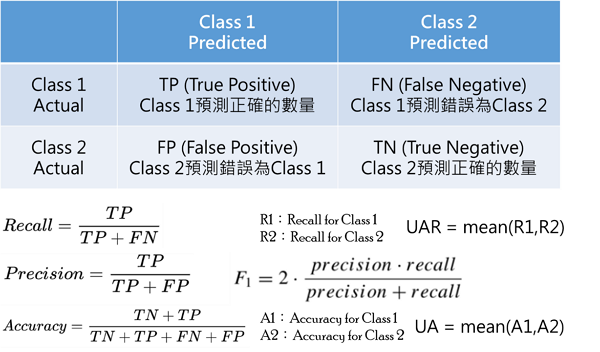 圖9 混淆矩陣的準確率、精確率、召回率、F1、UA與UAR計算公式
圖9 混淆矩陣的準確率、精確率、召回率、F1、UA與UAR計算公式5.調校演算法, 根據模型評估的效能狀況,進行演算法的改變或是參數的調整。
針對所設計的模型架構可計算出各個項目的指標效能與數值,但辨識率往往會與情緒類別、數量、語料庫、特徵擷取、演算法架構相關,只要其中一項變數有所改變,該指標數值也會大不相同。
以表1為例,使用的是IEMOCAP資料庫,4-class的情緒類別為喜(快樂和驚訝)、怒、哀、中性,5-class為上述的類別外再加入沮喪,可以看到在相同類別使用不同的架構會得到不同的辨識率,差異甚至可以達到10%以上,且在相同的架構下,當類別從4類變5類時則辨識率下降了9.3%。
表1 使用不同架構與不同類別數的辨識率(資料來源:[14])

表2使用的是IEMOCAP的4-class,可以看到當使用相同架構但不同的特徵擷取方式時,差異可達到8.1%。
表2 使用不同音訊特徵擷取方式的辨識率(資料來源:[15])

由於影響辨識率的變數非常多,因此在評估與調整自己的架構與模型之前,需要先瞭解目前所使用的資料庫與情緒類別的辨識率概況,以IEMOCAP挑選4種類別使用語音特徵來看,辨識率在53%~73%均落在可能的範圍內,若辨識率過低可能要重新審視整個過程中是否有哪一個環節需要進行調整。
結論
由於建構一個語音情緒辨識系統往往需要考量到資料庫、情緒類別、特徵擷取、分類器架構、評量指標等等,且每一項目都有要注意的環節和Domain know-how,一般讀者若沒有語音與機器學習概念,往往很難深入瞭解,因此希望透過本篇文章的說明,可以讓一般讀者能具備語音情緒辨識的基本概念,瞭解語音情緒辨識系統架構、流程與步驟,以及發展該系統時所需注意的事項和觀察重點,讓讀者能更容易的進入語音情緒辨識系統的世界。
參考文獻
[1] (2019)個人特質整合語音互動之深度情緒辨識技術—— 能夠依個人特質調整的 AI 語音情緒辨識模型https://www.futuretech.org.tw/futuretech/index.php?action=brands_detail&br_uid=107
[2] 陳靖明,梁凱雯,王家慶,張寶基,”結合心理特徵與情緒標籤訓練之語音情感辨識技術”, 2019 臺灣網際網路研討會
[3] Ekman, P. & Friesen, W. V (1969). “The repertoire of nonverbal behavior: Categories, origins, usage, and coding.”, Semiotica, 1, 49–98.
[4] PilgrimHui (2018) 论文笔记:语音情感识别(一)语音知识概览 https://www.cnblogs.com/liaohuiqiang/p/9916352.html
[5] (2019) 讓機器讀懂我們的心情,臺灣AI情緒辨識技術再突破 http://web.ee.nthu.edu.tw/p/16-1175-172261.php?Lang=zh-tw
[6] (2018) 論文筆記:語音情感識別(五)語音特徵集之eGeMAPS,ComParE,09IS,BoAW https://www.itread01.com/content/1545461946.html
[7] Semantic Scholar, Mel Frequency Cepstral Coefficients (MFCC) based speaker identification in noisy environment using wiener filter https://www.semanticscholar.org/paper/Mel-Frequency-Cepstral-Coefficients-(MFCC)-based-in-Chauhan-Desai/8bd177f74dd92ecc80728c515c6c3d6185251619
[8] 王選仲(2018) 分類演算法理論-SVM及XGB+CV https://ithelp.ithome.com.tw/articles/10194824
[9] (2020)維基百科,隱藏式馬可夫模型https://zh.wikipedia.org/wiki/%E9%9A%90%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB%E6%A8%A1%E5%9E%8B
[10] Sepp Hochreiter and J¨urgen Schmidhuber,“Long short-term memory,” Neural computation 9, 8,1997, 1735–1780.
[11] Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features,”end-to-end speech emotion recognition using a deep convolutional recurrent network,” In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China,20–25 March 2016; pp. 5200–5204.
[12] Mingyi Chen, Xuanji He, Jing Yang, Han Zhang,”3-D Convolutional Recurrent Neural Networks With Attention Model for Speech Emotion Recognition,” Published in IEEE Signal Processing Letters 2018.
[13] NTHU-NTUA,NNIME https://nnime.ee.nthu.edu.tw/
[14] Yue Gu, Kangning Yang, Shiyu Fu, Shuhong Chen, Xinyu Li, Ivan Marsic,” Multimodal Affective Analysis Using Hierarchical Attention Strategy with Word-Level Alignment,” Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 22 May 2018; pp.2225-2235
[15] Eesung Kim and Jong Won Shin,”DNN-based Emotion Recognition Based on Bottleneck Acoustic Features and Lexical Features,” 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 12-17 May 2019; pages 6720–6724. IEEE.
相關連結: 回182期_AI智慧應用專輯